| index.html / bots.htm / mhyst_w3s.htm |
 Back to Advanced |
by Mhyst |
First published @ Searchlores in January 2008 | Version 1.03 | By Mhyst
 |
|
Every day we have to deal with boring and repetitive tasks in front of the computer. Many times Ive found myself thinking how easy would be to computerize all those tasks in a program to which, afterwards, well only have to ask whatever we want it to do. I always wanted to own a virtual assistant. A program that would do for me all these things.
Internet searching is not always boring, but many times it is. Using search engines is each day more frustrating due to the increasing garbage index of Internet. So often we find pages that only have our search terms amidst other thousands that have been left there just to catch our attention. The SEOs evade the search engines ranking algorithms very easily, putting links to the website they want to promote everywhere: forums, blogs, wiki systems, etc. As a result, we have more and more noise and far less signal.
Ive ever thought that every good virtual assistant should have its own web spider or, perhaps, several web spiders: each one devoted to one kind of search. How handy would be to ask him what we wish and he would deal with all those details. But thats only, by now, a dream. J
The aim of this document is to put forward the structure and functionality of W3S and, at the same time, to describe a basic searching web spider. I hope this essay will bring somebody the possibility of making his own web spider.
This document is directed to:
In order to understand this work completely it would be ideal to have knowledge on the following stuff:
It would be great if you know the way a web browser connects to a web server to bring down a page. But you dont need that to understand some parts of this essay. And of course, I can tell you how to do the job:
In the section References you can find enough resources so to learn things I will tell you about. Some knowledge on Java programming language would help you to better understand the code snippets.
"A web crawler (also known as a web spider or web robot) is a program or automated script which browses the World Wide Web in a methodical, automated manner. Other less frequently used names for web crawlers are ants, automatic indexers, bots, and worms (Kobayashi and Takeda, 2000).
"This process is called web crawling or spidering. Many sites, in particular search engines, use spidering as a means of providing up-to-date data. Web crawlers are mainly used to create a copy of all the visited pages for later processing by a search engine that will index the downloaded pages to provide fast searches. Crawlers can also be used for automating maintenance tasks on a website, such as checking links or validating HTML code. Also, crawlers can be used to gather specific types of information from Web pages, such as harvesting e-mail addresses (usually for spam).
"A web crawler is one type of bot, or software agent. In general, it starts with a list of URLs to visit, called the seeds. As the crawler visits these URLs, it identifies all the hyperlinks in the page and adds them to the list of URLs to visit, called the crawl frontier. URLs from the frontier are recursively visited according to a set of policies."
This essay is about a web spider or web robot. When we speak about robots in computer science, we always refer to a program handling a electronic/mechanical part (this time a computer), and that is able to do tasks that are generally done by people. In this particular case, as were speaking about a web robot (casually webbot), we deal with a computer program designed to browse the WWW, or at least to visit some web pages.
Although we saw before that Wikipedia considers web robot and web spider as synonyms, in my opinion, a web spider is a kind of web robot. Web robots can be designed to do many things on the web. For instance, to log into a forum and post a comment. But these web robots dont take into account possible links appearing in the pages they visit. They generally have the needed page addresses hardcoded. What I consider truly web spiders are the web robots that take into account the links and whose mission is to follow them. The behavior of these web robots depends on the websites structure they happen to visit. They act like the real spiders sliding from link to link as if it were silk threads.
For a human being, browsing the web using a web browser is far easy. Even people using it for first time discover how easy and fun is it. But webbots dont have a web browser. They have to deal with web servers directly via TCP sockets and talk to them in HTTP (HyperText Transfer Protocol). Hence, to design a webbot you have to code part of a browsers functions to be handled by the bot intelligence. Fortunately, a bot doesnt need to render web pages. A huge part of the browsers code is devoted to do that: decode the html file, show the texts properly, load and show the pictures, load and play the sounds or music, interpret javascript, and a really long etc.
W3S is a searching web spider. But this time it wont work for a big search engine but for you. Youll have to tell it where to start the search (the seed) and what we want to search (the search terms) so to allow it to start surfing the web. Well never know where its search will finish following every link. The program offers several ways to control its web frontier, to say, the bot scope. Also its possible to not set limits and let it explore the web freely. In this last case, one cant know how much time it will take for it to finish the job.
At the present time, W3S searching abilities are based in taking account of times every search term appears in each visited page and showing the results in your web browser (html formatted). But it has every required module to be a good web spider. Furthermore, its modular design easily allows adding new searching algorithms or totally rewriting the bot reusing the basic modules.
HTTP client:
In charge for downloading a specified web page. Coding this module requires wide knowledge about sockets and some knowledge on HTTP. Most times, this kind of module stores the web page to a file.
Links collector:
Opens an html file and search for links which later will add to a links database. If youre going to code this module, you only need to know how to handle files and strings.
Query string analyzer:
Its goal is to process the query string in order to determine the search terms. W3S hasnt query string syntax; you have to enter some words or sentences comma separated. And then, this module only has to detect the comma character and separate the search terms.
Searching algorithms:
Its function depends on the webbot task. W3S, being on a starting phase, only counts search terms occurrences. This module is the web spiders part you have to think about the most carefully you can. The cleverness of the spider depends on this module.
Starter:
Contains the spiders main loop. For each iteration the module handles a link until there are no more links left. It has to call every other module in the correct order.
User interface and results presentation:
Can be graphic, console, etc. In first place it must serve to allow the user to state the webbot configuration parameters and to launch the starter. It also must provide a way to show the results. W3S stores the results in an html file that is shown in your default web browser.
When one decides to write a program, the language choice is not always simple. Even after writing the program, one thinks whether the choice was good or not. You can never be sure. Thats so because programmers learning process involves studying many programming languages, and as if it werent enough torture, almost all programmers decide to learn new programming languages on their own. Lately its compulsory to know many languages because there are languages for different tasks. For instance, on a dynamic web project youd need to know HTML to code the pages, an application server language (PHP, Java Servlets, JSP, ASP, C#, etc), some javascript, maybe XML, SQL (if youre going to deal with databases), etc.
//Begin of code
//Initialization
//This is the object well use for the http connection.
HttpURLConnection http;
//Though we need a URL
URL url = new URL(http://www.searchlores.org);
//Now http represents our connection with the web server
http = (HttpURLConnection) url.openConnection();
//Between the HTTP methods (GET, PUT, POST, HEAD, etc)
//we choose to use GET
http.setRequestMethod("GET");
//Setting required request headers
//Some servers will answer correctly without specifying
//request headers, but some wont.
//For instance, google wont work without it.
http.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)");
http.setRequestProperty("Accept", "text/html");
http.setRequestProperty("Accept-Encoding", "none");
//Connection
//Thats where the real connection to the web server is made.
http.connect();
//HTTP response code analysis
//200 = OK, 201 = Created, 202 = Accepted, etc.
//Every code starting by 2 is considered valid.
//The rest of the codes may be errors.
//For instance: 400 = Bad request.
//The worse possible codes are those starting by 5.
int code = http.getResponseCode();
if (code < 200 || code > 300) {
System.out.println(http.getResponseMessage());
http.disconnect();
return;
}
//Write the page to file
BufferedReader in = new BufferedReader(new InputStreamReader(http.getInputStream()));
String line;
PrintWriter out = new PrintWriter(new FileWriter(searchlores.htm));
while ((line = in.readLine())!= null) {
out.println(line);
}
http.disconnect();
out.close();
//End of code
W3S collects a lot of links (as many as its web frontier allows). Its very important to store it carefully so that doesnt become lost and also to avoid visiting the same page twice (what would lead us to an infinite loop). The collected links are stored in RAM via classes Vector and Hashtable. The faster class Vector is used to quickly get the next link to visit, while the key identified hash table is used to test if the current link was already visited.
The user interface is a graphic interface developed with Java Swing. It contains only the basic needed controls.
For the rest of the modules I think we only need a set of string functions. Thats enough well with the Java class String.
HttpToFile
It is the HTTP client. As it tells its name, it brings down a page and stores it in a file.
Log
Logs recording Subsystem. Its used to keep track of process incidents or registered errors. (http.log)
Link y LinksManager
Link object and Links database respectively. They are the needed system to store links for the webbot job.
LinksExplorer
W3S Starter. It also contains the Links collector, the query string analyzer and the very search algorithms.
W3s Graphic User Interface
As I stated before its made in Java Swing. Allows the user to enter the webbot configuration parameters and to launch the starter module: LinksExplorer. It is also in charge for showing the results.
Do you want to explore a website for things you're interested in but you don't have time to do it? A personal web spider can do that for you.
A personal web spider can be used to explore the web in the most wide meaning of the word, giving as seed a highly connected page. Also, a good idea is to make a common search first (for example in Yahoo!) and establish the Yahoo! search results page as a seed. You can also use the spider to explore a deep website (surely, this way, youll discover pages you never dreamed it existed).
The spider is able to read internet pages. During the reading, apart from seeking for the search terms you specified, the bot collects links. As soon as it ends reading a page, the bot has to write the results in some way, and then it gets a new link from its links collection and starts again.
The bot does that until there are no more links to process, that's why the search process can last for a long while.
Lets see how the common spider modules we saw interact to do the job:
Starter Module: Parameters (seeds, searchQuery, webFrontier)
create LinksDatabase;
for each seed in seeds do
add seed to LinksDatabase;
end for;
//Turns the query string into a search terms array
//depending on the query syntax
searchTerms[] = SearchTermsAnalysis(searchQuery);
for each link in LinksDatabase do
//webFrontier is actually a set of conditions
//that must be evaluated for each link
if link in webFrontier do
webPageContent = HttpClient.download(link);
results += searchAlgorithms(searchTerms, webPageContent):
//This function will search the
//web page content for links
//and will store the found links
//in the LinksDatabase
searchForLinks(webPageContent);
end if;
end for;
show (results);
End Module;
The webbot user interface will rely upon retrieving the user orders and calling the starter module telling it the seeds, the query string and the web frontier. Upon process end, it should show us the results.
Now, its time to see the actual behavior of W3S:
W3S has a similar structure. Now well see the differences.
W3S works with a unique seed. This may change in the future, though I suppose that some people will find a way to circumvent this limitationJ.
W3S lacks any syntax, so it doesnt have a complex query string analyzer. It only separates items from a comma delimited string. If the user enters spaces before or after a comma it is considered as part of the previous term or the next respectively. Due to this feature, a search term can be a complete sentence. The only character you can never use as part of a search term is, precisely, the comma for obvious reasons. Im open to suggestions to solve that.
The HTTP client stores the every web page to a file.
The links database is stored in the RAM, just as we saw in the previous section. This can put a limit to the number of links that the bot is able to store. But I dont think it is an issue by now. Besides, the data being in RAM makes the access really fast.
The web frontier can be controlled in many ways Ill explain now:
About search algorithms, W3S only have one: count search terms occurrences on every visited page.
The links collector works only with the anchor tag (<a href=...).
The results are stored during the process in a html file (salida.htm). The file opens in your default navigator when W3S finishes crawling. This part uses RUNDLL Windows library, so if youre running a different platform it wont work. But you always can open the file manually.
Both, the defined generic search spider and W3S, still require the user action. The results consist on a list of links and their number of appearances of every search term. Hence, when the webbot finishes its job, the authentic work for you begins. In some cases, the appearance one single time of a term will mean to rule out one page, while others a high number of occurrences for a term will bring interest to a page. Youll have to decide how to evaluate the results. Thats the most important part of the search. If you fail evaluating the results, the bot wont help.
Even so, the bot has proved to be useful for me. Please, consider that using this kind of bot will give you a totally different searching experience. Enjoy it!
In short, W3S is only a source of data to help us. Seekers will be still needed in this world for many years (lets hope it xD).
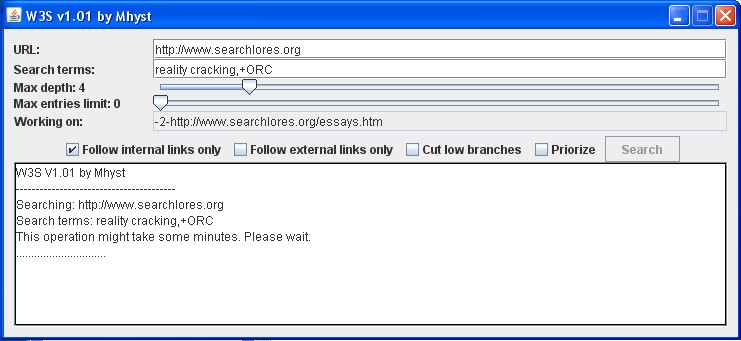
Obviously, the program is still in a very initial phase. Many improvements can be made and, of course, will be made:
Rewriting LinksExplorer: Id like to separate it into the conceptual modules I described. That will make easier to add extensions.
The Searching Algorithms module should be easily extensible so that we can mount new algos on the fly.
It would be good to create its own query string syntax.
The current Links Collector only considers the anchor tag (<a>). There are many other ways to add links to a web page and that module should use as much of them as possible. For instance, the new module should identify frames and follow each frame source as a link .
Another idea is to make a console versión. Thats an easy modification and many people would like it.
If you know about my other essay, about a program called Deliverer; I have in mind writing a W3sTranslator to integrate W3S in Deliverer. That would allow sending W3S requests by email and sending the results also by email.
At last, working in the bot intelligence is a major issue and improving the results appearance. Perhaps, some day, well reach the point in which a bot can decide for us what pages are worthy and which not. Im not sure if that would be a better world. In the meanwhile we must continue working in the pursuing of light, as always did.
Thank's fravia+ for publishing it and thank you for reading it. :)
Mhyst