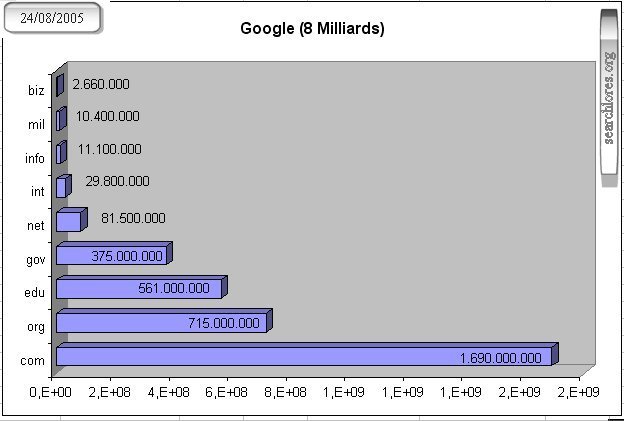
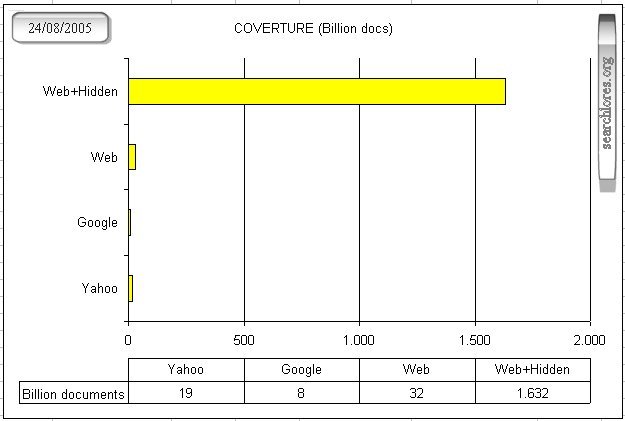
|
VERY useful findings Google Web APIs Google in depth An easy way to search Google's cache How big is google's index |
||











New introduction | Before even beginning | Old Introduction
Some useful & simple googolian know hows | Spamming | Query parameters
Advanced operators | Various oldies about google | Useful findings | Googlette
Daterange:Shally Steckerl explains as_qdr | Google's daterange, by Ritz | How does google work?